

En horas el INDEC va a darnos los datos sobre la inflación de febrero. El jueves pasado, con toda la información en sus mochilas, la inteligencia económica local agrupada en el REM nos habló de un 2,7%. Este lunes la Ciudad de Buenos Aires reportó que los precios para los porteños subieron durante febrero 2,6%. En voz baja se habla que el gobierno se haría una fiesta si el número final está debajo del 2,5%.
Febrero, una inflación en baja que no alcanza
Que la inflación de febrero sea mayor a la de enero, sería casi una anormalidad. Lo esperable es una baja, que seguramente el Gobierno intentara “vender” como el reinicio del proceso de desaceleración inflacionaria. Pero: “una golondrina no hace verano”…, máxime cuando la acaban de bajar de un misilazo.
-
Caputo nombró a joven economista al frente de las estadísticas mineras y energéticas del INDEC
-
El Gobierno insiste en que la inflación quebrará el umbral del 1% en agosto

En horas conoceremos los datos del INDEC sobre la inflación de febrero. Ese dato ya quedó viejo y no nos sirve para entender la nueva realidad. El gobierno no podrá festejarlo.
Una fiesta porque podrían hablar del reinicio del proceso de desaceleración inflacionaria que parece haber acabado hace diez meses (claro que esto depende de si escandalete “Adorni”, que ya le aguó la fiesta al “Argy Week” en Nueva York, se diluye o no).


Lo que tenemos son tres datos que seguramente no alcancen a reflejar la sensación de bolsillo que tenemos cada uno de los argentinos/as, atenazados entre precios que aumentan más de 2% e ingresos que prácticamente no se mueven o lo hacen debajo de eso, incrementando nuestra percepción de la “brecha inflacionaria”.
Frente a esto, y sin riesgo de quedar como una figura risueña, el Presidente Milei no solo insiste con que la inflación de agosto será menor a un digito, sino que ahora adelantó la fecha de quiebre al mes de julio: “Entre julio y agosto la inflación va a empezar con cero”… ojalá tenga razón.
Frente a esto, la ironía de la semana fue el tweet que lanzó el ministro de Economía el viernes pasado, rápidamente integrado a la red mediática libertaria, destacando una serie de elogios de John C. Cochrane a Javier Milei y a la Argentina (lo que, dicho sea de paso, no se ve en el original), soslayando su “Inflation remains 2% per month, but that is the government’s target”.
No sabemos si una inflación del 2% mensual es o no el verdadero objetivo del gobierno, lo gravitante de su comentario es la implicancia que difícilmente bajaría del 2% mensual (el yanqui soslaya que en los últimos ocho meses el incremento de precios prácticamente se duplicó y hace tres que estamos más cerca del 3% que del 2%). La receta nos la da en su libro, que no adscribe a la receta libertaria, y ni “el Javo” ni “el Toto¨ -que alguna vez se vanaglorio de no leer “papers”- parecen haber ojeado.
A pesar de los que insisten que es más difícil reducir el crecimiento de los precios de la zona del 2% a menos del 1%, que hacerlo de dos cifras a una, la realidad histórica señala que esto ocurrió en la Argentina durante los años 1961, 62, 64, 66, 67, 68, 70, 71, 72, 73, 91, 2002 y 2016. Así que pueda que no sea fácil, pero está lejos de ser algo heroico.
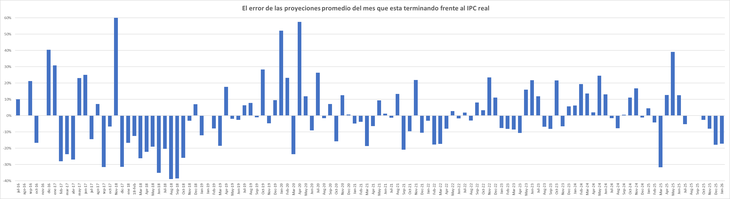
Un mes atrás vimos a los “muchachos del mercado” quedar en offside unos pocos días después que se difundiera su última estimación para la inflación de enero, 2,4% -datos recogidos entre el 28 y 30 de enero- y el Organismo Oficial reportara 2,9%. Puede no parecer demasiado, pero es un fabuloso error de 17%.
Lo que hicieron desde el gobierno y los intelectuales económicos fue apuntar a la suba de los llamados “precios estacionales”, para justificar que el IPC creciera ese mes al máximo en 10 meses. Lo que no alcanzaron a explicar es por qué los estacionales son más difíciles de prever que el resto de los precios.

Ahora ocurre algo similar. A principios de mes proyectaron que la inflación de febrero rondaría 2,1%, pero como vimos sus últimas estimaciones, a medida que iban recogiendo los datos del día a día, ya hablan de 2,7%. Una diferencia casi abismal que demuestra que su capacidad de “adivinar” lo que sucederá con la economía en el corto plazo muy buena no es.
Personalmente no sabemos qué valor nos dará a conocer el INDEC, pero la chance de un febrero por debajo de enero luce elevada.
Las estadísticas
El IPC viene de enhebrar una seguidilla de cinco meses consecutivos de suba (no son ocho porque aún redondeados a 1,9%, el incremento del IPC de julio pasado fue 1.902% y el de agosto 1,876%).
Desde 1959 que es cuando tenemos datos confiables (durante el periodo de intervención K tomamos el IPC Congreso) solo dos veces -a julio de 1994 y a abril de 2023- el IPC anotó cinco meses consecutivos de suba (aceleración de la inflación) y una sola de ocho. Esto es, fenómenos de este tipo están lejos de ser algo habitual (1 de cada 263 seguidillas), lo que sugiere que, si bien conllevarían algún tipo de información, por una mera cuestión estadística, la chance que febrero venga debajo de enero pareciera ser elevada.
Desde un punto de vista más “científico” decimos que la variación mensual del IPC no se mueve a “las locas” (no sigue un proceso de “ruido blanco” o “random walk”) sino que lo que sucede en un mes, tiende a afectar lo que ocurrirá al mes siguiente. Eso que definimos como “estacionalidad”.
Lo que sigue no tiene que preocupar al lector corriente, pero cuando vemos los correlogramas (general y parciales) y aplicamos los tests estadísticos más usuales: de Corridas (que sugiere que los movimientos del IPC tienden a cambiar más de lo que podríamos esperar por el azar puro) y los de Dickey-Fuller Aumentado, Breusch-Godfrey y Ljung-Box Q, que es uno de los favoritos para el análisis de precios, lo que vemos para decirlo de la manera más simple posible es que, si bien en términos de persistencia la inflación en Argentina pareciera exhibir históricamente algo así como una memoria de largo plazo (los sucesos se prolonga en el tiempo), en términos de la causalidad directa de los eventos, su memoria ha sido “corta”, apenas de un mes (en estadística hablamos de un proceso autorregresivo de orden 1).
Esto puede parecer contradictorio, pero no lo es. Lo que importa para este mes es lo que sucedió el mes pasado, lo que vino antes es un simple eco que se ha venido prolongando en el tiempo. Así que una vez que lo quitamos, ese “ruido” pierde cualquier influencia (si no le gusta el argumento, piense en el pronóstico del tiempo).
Es por esto por lo que cuando la inflación se acelera o desacelera de un mes a otro (la segunda derivada), el siguiente cambio en la aceleración tiende a darse en un sentido contrario (desacelerándose o acelerándose) dándole una base -si se quiere estadístico/histórica- a la idea de que, porque ya subió durante demasiado tiempo o subió demasiado, el IPC de febrero sería inferior al de enero (no es algo obligado, pero no debe sorprendernos que así ocurra).
Si el gobierno no tomó esta línea argumental para justificar la eventual baja de febrero es porque que implica reconocer que el proceso de reducción del IPC iniciado en enero de 2024 se quebró hace tiempo o, dicho de otra manera, que el plan desinflacionario hace tiempo no está funcionando como se esperaba, y cualquier reducción eventual de la inflación en los próximos meses, podría no ser más que eso, algo eventual.
El camino de los adivinos
Hoy la pregunta que se hacen de los economistas y los Bancos Centrales no es si la inflación es algo predecible, sino como hacemos para predecirla.
Las estadísticas y la teoría monetaria nos dan alguna base para entender cómo se comportó y cómo debiera comportarse la inflación, pero esto no significa que nos permitan predecir con exactitud cómo se va a comportar en el futuro.
Posiblemente el primero que desarrolló un modelo que permitía predecir el nivel de la inflación, fue Irving Fisher, en 1911 con su M*V=P*T (donde M es la cantidad de dinero, V la velocidad con la que se mueve ese dinero, P el nivel de precios y T las transacciones o producción de la economía).

Pero esto no era un modelo predictivo. El primer modelo específico de predicción de precios parece haber sido el de C.F. Sarle, que en 1924 desarrollo una fórmula buscando adelantar el precio de la carne de cerdo en base a distintas variables: el precio promedio de las acciones de los últimos seis meses y de la carne de cerdo, y los precios promedio de los últimos doce meses del maíz y el radio precio maíz/cerdos.
Posiblemente no sabía nada de Sarle, pero en 1936/39 Jan Tinberegen (junto a Ragnar Frisch el primer premio Nobel en economía de la historia) de alguna manera lo siguió y en lugar de considerar los precios como una función de la cantidad del dinero (a lo Fisher), los analizó como algo emergente de la interacción de la oferta y la demanda de bienes, el costo laboral y los salarios, los precios importados, las condiciones del crédito y la inversión e incluso de su comportamiento previo, en su análisis de la economía holandesa y norteamericana, cuando elaboró los primeros grandes modelos macroeconómicos (para EE.EE., desarrollo 48 ecuaciones analizando más de 50 variables).
Siguiendo a Tinbergen, en 1950 L. Klein desarrolló el primero de sus modelos predictivos apelando a seis ecuaciones, que fue puliendo y ampliando durante las siguientes décadas. En 1955, junto a A. Goldberger incorporó la idea de las expectativas sobre los precios y para 1963 presento el “Wharton Econometric Forecasting Model”, creando WEFA, el primer servicio comercial de predicciones que considerando unas 47 ecuaciones analizaban cerca de 100 variables para predecir unos 80 indicadores económicos, hasta un año de plazo... entre ellos, la inflación y el PBI cuatrimestrales.
Así Klein convertía lo que hasta entonces habían sido modelos académicos en herramientas prácticas de negocios, siendo rápidamente contratado por la Reserva Federal (Fed) y otras agencias del gobierno, universidades e incontables empresas. En 1969 apareció Data Resources y en 1974 Chase Econometrics, monopolizando entre las tres la industria de las predicciones económicas norteamericanas hasta llegada la década de 1980.
Por ese entonces el modelo de WEFA empleaba unas 600 ecuaciones que se alimentaban de unos 800 diferentes, generando casi 10.000 proyecciones individuales (el horizonte se había extendido a 3 años) que eran analizados y “pulidos” por cientos de economistas analistas.
Pero llegaron los 80´s. El primer gran golpe a estos grandes modelos macro había sido su manifiesta incapacidad de predecir el shock petrolero de los 70´s y la consiguiente estanflación de la que comenzaron a recuperarse hacia fines de la década.
De lo que no pudieron recuperarse es de un “paper” que publicó en 1980 Christopher Sims (Macroeconomics and Reality; se ganó el Nobel en 2011) cuestionando estos grandes modelos y proponiendo el empleo de modelos con Vectores de Autoregresión (VAR), infinitamente más sencillos, pero tanto o más eficaces.
Hasta entonces el paradigma era, “más datos + más ecuaciones = más detalle = mejores predicciones”. La nueva propuesta, era “solo los datos relevantes y las ecuaciones que tuvieran una base teórica sólida, generaban predicciones confiables e intelectualmente defendibles”. Para el caso en particular de la inflación, Sims dice que con conocer la base monetaria simple (M1), la Producción Real (PBI), el Nivel de los precios, la tasa de interés, los precios importados y la tasa de desocupación, se captura prácticamente todo lo que era relevante.

Tal vez el trabajo de Sims hubiera pasado desapercibido, pero en enero de 1975 se comenzó a vender un “chiche”, que lo habría de cambiar todo, la Altair 8800, una computadora sin teclado, monitor ni software, que uno mismo podía armar. En 1976 Apple lanzó su primera computadora y en agosto de 1981 IBM puso en el mercado las primeras PCs, abriendo la puerta a que cualquiera accediera a la capacidad de cálculo necesaria para elaborar sus propias proyecciones macroeconómicas.
En paralelo los bancos centrales, las universidades y hasta alguna de las grandes corporaciones habían comenzado a desarrollar sus propios departamentos de predicciones. Así, para mediados de los 80´s, el poder de quienes habían monopolizado hasta entonces la información sobre el futuro, se fue diluyendo y la capacidad de generar predicciones/información, comenzó a convertirse en un commodity.
El camino de los sabios
A diferencia de otras, en esta historia el mundo de la academia la corrió de atrás. Recién en 1958 A.W. Phililips desarrolló lo que podemos considerar como el primer modelo estadístico o econométrico que eventualmente usarían los economistas como predictor de la inflación.
Estrictamente el modelo de Philips hablaba de la relación entre los sueldos y los salarios, no de la inflación, pero en 1960 P. Samuelson y R. Solow lo popularizaron como una herramienta para vincular el empleo con la inflación.
Por alguna razón Samuelson y Solow -e incluso Phillips- ignoraron olímpicamente la contribución del holandés, promocionando únicamente a Phillips. Si bien Tinbergen fue quien elaboró el primer modelo econométrico vinculando el empleo y los salarios, Fisher ya había intentado verificar de manera estadística esta relación, que había descripto David Hume en 1752 y que Paul Sultán graficó un año antes que Phillips.
Keynes había hablado de la “brecha inflacionaria” (la inflación crecía cuando una sociedad intentaba gastar más dinero que lo que producía la economía), pero nunca formuló un modelo especifico. Esto es lo que vino a solucionar la “Curva de Phillips” y lo que la hizo tan popular en el mundo de los economistas
En 1967 M. Friedman y E. Phelps, de manera independiente y simultánea, cuestionaron la idea de la “Curva de Phillips” como predictor, ya que dejaba de lado el efecto de las “expectativas inflacionarias”. Si la gente esperaba un mayor incremento en los precios, los salarios y precios tenderían a ajustarse en el mismo sentido.
La estanflación de los 70´s fue la prueba práctica de la inutilidad del modelo keynesiano.
Esto tomó más impulso luego del “paper” de Robert Lucas en 1976 (anticipado en su conferencia de 1973) que en pocas palabras advertía que “usar relaciones estimadas históricamente para predecir los efectos de nuevas políticas no es confiable, porque el comportamiento de la gente cambiara si las políticas cambian”. Con esto introducía la idea de las “expectativas racionales” que había desarrollado J.F. Muth en 1961, al mundo de la pronosticación (acá no debería olvidar las contribuciones de Sargent y Wallace).
En 1982 F.E. Kydland y E. C. Prescott en 1982 (ganadores del Nobel en Economía, 2004) presentaron un modelo que incorporaba las expectativas y describía los ciclos económicos como la respuesta eficiente de la economía a shocks reales, como los cambios tecnológicos (el modelo RBC).
Con este “background”, en 1996 la Reserva Federal lanzó el primero de sus modelos predictivos a gran escala, reemplazando al MPS que venía utilizando desde 1970. Acá vale una salvedad, si bien se pueden asociar, este modelo que seguía a Sims y K&P, era mucho más simples y flexibles que el MPS, que en el fondo no era más que otro WEFA.
En 1993, John Taylor dio a conocer lo que hoy conocemos como la “Regla de Taylor”, distinguiendo el corto del largo plazo: si bien en última instancia la inflación era un fenómeno monetario, las variaciones de corto plazo dependían de las respuestas de los gobernantes a factores observables, como la propia inflación y la producción. Con esto salvaba los problemas de la curva de Phillips y daba un puntapié al neo-keynesianismo.
De esta “melánge” de monetarismo, economía clásica, expectativas racionales, y neo-keynesianismo surgieron los modelos de Equilibrio General Dinámico Estocástico (DSGE), una representación matemática de toda la economía, buscando predecir como reaccionaba ante diferentes eventos y políticas a través del tiempo.
La Fed lanzó el primero de estos modelos en 2005 -poco después que los centrales de Canadá, Suecia, Inglaterra, Nueva Zelandia, etc.-, el EDO, que pasaba de las 70 ecuaciones del FRB/US a no más de 30 y cuyo principal objetivo era el estudio del efecto de sus políticas. En paralelo creo el SIGMA (40 ecuaciones) para analizar la transmisión de los precios internacionales a la inflación local, varios modelos VAR de tipo Bayesiano, otros de Factor Aumentado y distintos integrantes del Sistema de la Fed elaboraron sus propios modelos DSGE, etc.
A grandes rasgos, para sus predicciones inflacionarias la Fed utiliza hoy unos 40 modelos (2 FRB/US, 5 DSGE, casi 8 VAR, 5 Phillips, 10 modelos sectoriales, 8 regionales, etc.), que se subdividen en toda una suite de modelos parciales, cuyos resultados son tamizados por más de 600 economistas.
Irónicamente un trabajo de la Fed de Chicago de 2023 determinó que, en el caso norteamericano, un simple modelo AR(1) que básicamente pronostica la inflación en función de su propio “lag” -como al que parece obedecer la inflación en Argentina-, provee resultados significativamente más confiables que los modelos más complejos.

Lo que hacen los yanquis puede parecer excesivo, pero el Banco Central de la India, por caso, procesa la información de una suite de 216 modelos (algunos estadísticos, AR, ARMA, VAR, etc; otros “machine learning”, SVM, Random Forest; otros “Deep learning”, LSTM; e incluso aplican el “random Walk”) buscando una estimación única de la inflación. Claro que el récord se lo lleva el Banco Central Europeo (BCE) que analiza los resultados de más de 2.300 modelos parciales.
Nota: En 2007/8 el BCRA desarrolló el ARGEM, que en 2009 se recalibró en el ARGEMmy, pero la realidad es que nunca se implementaron de manera efectiva (estos modelos están operativos en el resto de Latinoamérica hace más de 15 años). Históricamente el Central apeló para sus proyecciones a modelos VAR y en menor medida a modelos de equilibrio parcial o monetarios, si bien desarrolló un Pequeño Modelo Económico (SEM) para las proyecciones macro de rutina, hoy nuestro Central parece más orientado al empleo de modelos de “nowcasting”, lo que es razonable teniendo en vista la poca confiabilidad de la información.
Predecible, pero no probable
Como vemos, a pesar de la idea que “lo breve, si breve, dos veces bueno” (lamentablemente este comentario no lo es), o como se dice en el mundo de la estadística, “parsimonia y foco sobre la información correcta puede ser tan valiosa como la complejidad”, esta cuestión de proyectar la inflación se ha venido haciendo cada vez más compleja y complicada apareciendo más y más modelos.
La pregunta de fondo es si esta complejización ha servido de algo. Lo que mejor parece andar son los modelos de Now-casting (de fácil ejecución, pero uso intensivo de datos) dentro de un horizonte de 1 a 3 meses. Luego tenemos los Modelos de Regresión Penalizada de Aprendizaje de Máquinas (Lasso o Red elástica), cuya eficiencia es menor y no va más allá de 1-6 meses. En tercer lugar, los Modelos de Suma Descompuesta de Ciclos, que se utilizan para proyecciones hasta dos años,
En el cuarto, aparece la IA y los modelos de Redes Neuronales, que parecen prometer mucho si bien exhiben errores significativos, y en quinto los Modelos de Ensamble o Crowdsourcing que agregan las predicciones de la gente y si bien han demostrado cierta precisión a mediano plazo, los de Now-casting los superan el 10%20% de las veces.
Debajo de estos vienen los DSGE, VAR y los otros grandes modelos que ya vimos emplean los bancos centrales, inversores institucionales y asesores económicos.
Entre todo esto tenemos las casas de apuestas (Kalshi), cuyos resultados son bastante razonables.
Claro que si lo que quiere es algo más sencillo, el mes pasado se presentó un modelo incluso más simple que el anterior para predecir la inflación en el caso de los países del G7, con mejores resultados que los mecanismos más complejos. Arrancando con alguna de las predicciones más confiables sobre la inflación (la del FMI) la idea es analizar cuán errados fueron estos pronósticos en los últimos años. Finalmente se combinan estas dos piezas de información y se establece un intervalo de predicción.
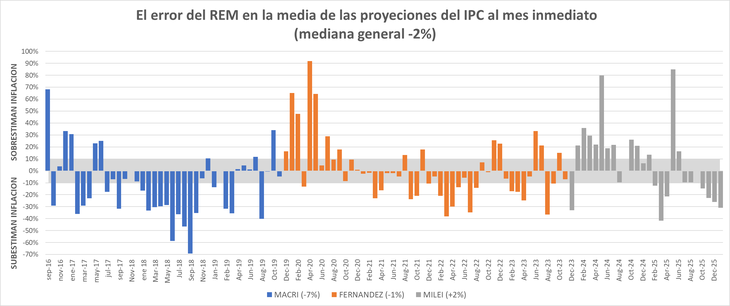
Los datos del REM son alarmantemente malos. Desde 2016 el 71% de las estimaciones sobre el incremento de los precios minoristas para el mes que sigue le erraron en más del 10% y 50% por más del 20%. Para el mes corriente el 54% le erraron por más de un 10% y el 28% en más del 20%.
Jugando a las proyecciones, si tomamos la proyección de enero para febrero y aplicamos el modelo del G7 podemos esperar con una certidumbre del 80% (es decir en 4 de cada cinco veces, lo que usualmente se considera una buena predicción) que el número que de hoy a conocer el INDEC estará entre 2,6% y 1,6%. Cualquier cosa más allá de esto… agarrarse.
¿Qué hay sobre marzo? Los muchachos del REM hablaron de 2,5%. Si bien apenas pasaron algunos días, cuesta no pensar que otra vez le erraron al tacho.









